DeepSeek 首次拉北大署名開源推理框架 DSpark|高並發下單用戶提速 60%-85%,吞吐反而再漲 51%-661%
DeepSeek 首次拉北大署名開源推理框架 DSpark|高並發下單用戶提速 60%-85%,吞吐反而再漲 51%-661%
DeepSeek 與北京大學在 6 月 27 日聯合放出推理加速框架 DSpark,相關論文掛上 arXiv,訓練代碼、評估腳本與草稿模型 checkpoint 同步進 GitHub 的 DeepSpec 倉庫,作者列表裡有梁文鋒。這是 DeepSeek 第一次和高校合作署名開源底層推理組件。
正常做推測解碼(speculative decoding),加速比和吞吐量是蹺蹺板:壓低首 token 延遲就要犧牲批次併發,反之亦然。DSpark 直接把兩頭一起拉,在同等吞吐水平下,單用戶生成速度比此前生產基線 MTP-1 提升 60% 至 85%;如果反過來鎖延遲,吞吐量按 SLA 檔位提升 51% 至 661%。這個區間在生產級 LLM 服務裡很罕見。
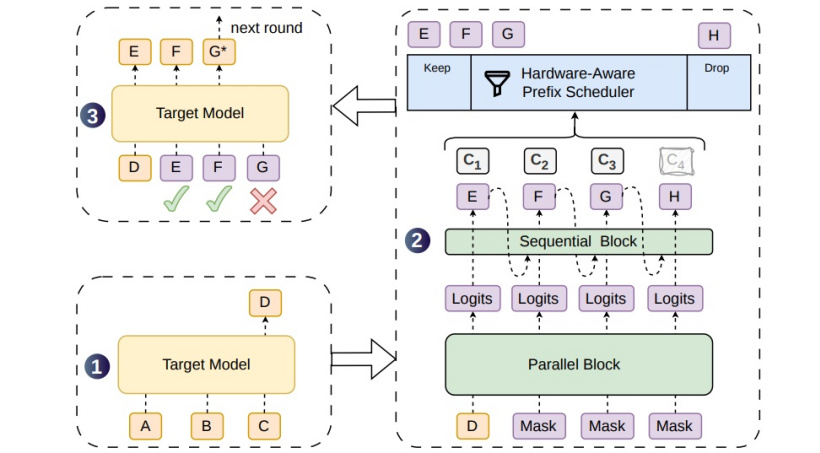
技術上做了兩件事。一是 半自回歸候選生成:並行主幹網路一次性吐出多個候選 token,再用一個輕量級順序模塊把 token 之間的依賴回填進去,繞開純並行草稿質量差、純自回歸草稿太慢的死結。二是 置信度調度驗證:模型自己對每個 token 給存活概率打分,硬體感知調度器根據當前 batch 形狀動態決定要驗證多長,把 GPU 算力榨乾。
DSpark 已經跑在 DeepSeek-V4-Flash 和 V4-Pro 的預覽版服務引擎裡,Hugging Face 上的 `deepseek-ai/DeepSeek-V4-Pro-DSpark` 就是 V4-Pro 基座 + 外掛的 DSpark 模塊,MIT 協議。橫向測試裡,DSpark 在 Qwen3 4B/8B/14B 和 Gemma4-12B 上同樣能套,平均接受長度比 Eagle3 多 26.7% 至 30.9%,比自家上一代 DFlash 多 16.3% 至 18.4%。
這次 DeepSpec 一次性開了 DSpark、DFlash、Eagle3 三套草稿模型的訓練全流程,意味著任何接 vLLM、SGLang 的團隊都能直接拿去微調自家模型。國內推理棧裡,能把高並發速度和吞吐同時拉到這個量級且願意把訓練代碼一併放出的,目前只此一家。
via 新浪財經 / IT 之家 / Hugging Face / 新浪科技
DeepSeek 與北京大學在 6 月 27 日聯合放出推理加速框架 DSpark,相關論文掛上 arXiv,訓練代碼、評估腳本與草稿模型 checkpoint 同步進 GitHub 的 DeepSpec 倉庫,作者列表裡有梁文鋒。這是 DeepSeek 第一次和高校合作署名開源底層推理組件。
正常做推測解碼(speculative decoding),加速比和吞吐量是蹺蹺板:壓低首 token 延遲就要犧牲批次併發,反之亦然。DSpark 直接把兩頭一起拉,在同等吞吐水平下,單用戶生成速度比此前生產基線 MTP-1 提升 60% 至 85%;如果反過來鎖延遲,吞吐量按 SLA 檔位提升 51% 至 661%。這個區間在生產級 LLM 服務裡很罕見。
技術上做了兩件事。一是 半自回歸候選生成:並行主幹網路一次性吐出多個候選 token,再用一個輕量級順序模塊把 token 之間的依賴回填進去,繞開純並行草稿質量差、純自回歸草稿太慢的死結。二是 置信度調度驗證:模型自己對每個 token 給存活概率打分,硬體感知調度器根據當前 batch 形狀動態決定要驗證多長,把 GPU 算力榨乾。
DSpark 已經跑在 DeepSeek-V4-Flash 和 V4-Pro 的預覽版服務引擎裡,Hugging Face 上的 `deepseek-ai/DeepSeek-V4-Pro-DSpark` 就是 V4-Pro 基座 + 外掛的 DSpark 模塊,MIT 協議。橫向測試裡,DSpark 在 Qwen3 4B/8B/14B 和 Gemma4-12B 上同樣能套,平均接受長度比 Eagle3 多 26.7% 至 30.9%,比自家上一代 DFlash 多 16.3% 至 18.4%。
這次 DeepSpec 一次性開了 DSpark、DFlash、Eagle3 三套草稿模型的訓練全流程,意味著任何接 vLLM、SGLang 的團隊都能直接拿去微調自家模型。國內推理棧裡,能把高並發速度和吞吐同時拉到這個量級且願意把訓練代碼一併放出的,目前只此一家。
via 新浪財經 / IT 之家 / Hugging Face / 新浪科技